谈谈大模型时代下的个人知识管理
自 2023 年 3 月份开始使用 ChatGPT 以来,我一直在探索如何将 LLM 加入到我的知识工作流中,同时也在思考有了 LLM 这个看似无所不知的助手之后,我先前做知识管理的手段是否还有价值,或者说还有没有必要做知识管理。
在没有大模型之前,我的知识工作流大概就是遵循 输入-处理-输出-再输入 的螺旋式循环。在执行了 5 年的知识管理的过程中,我提炼出了一些适合我个人的知识管理手段,包括知识连接、知识复习、结构化知识展现等。这些在我的知识管理系统 https://b.ismy.wang 中有很好的体现。
但有了 LLM 之后,我不禁思考:有了 LLM 这样一个无所不知的助手之后,在碰到问题时,直接去问它就好了,是否还有必要费劲心力去整理、消化、结构化这些知识?我的答案是:仍需要。
LLM 的一个重大缺陷当然就是幻觉,它只是一个概率模型,有人称 LLM 为“人类最大似然估计”,它压根不懂自己到底在说些什么,只是尽力地使用模型去拟合用户的输入,也不具备推理能力,至少在 2024 年 11 月的今天是这样的。
为了解决幻觉这个问题,现在业界采取了一些诸如 RAG 的手段,将可信性度更高的知识作为 LLM 的上下文来限制它的输出,使输出更加可信。
所以我觉得继续做知识管理,拥有一份自己的知识体系仍是必要的。原因如下:
- 一份属于自己的知识体系能够作为 LLM 的可信知识来源,让 LLM 利用你的知识体系回答你的问题是个不错的选择。
- 在整理自己的知识体系的过程中,可以通过连接、结构化手段抽象、利用现有的知识推理出更深层次的知识。
那么 LLM 可以在知识管理的工作流中帮我们做些什么?目前我用 LLM 在知识管理的各个阶段都做了一些不错的尝试:
- 利用 LLM 的文本概括功能快速点明文章主题,加快阅读速度,或者针对一些长文章,询问我所关心的问题,方便我结构化知识,将知识安排到知识体系中的合理位置。

- 利用 LLM 中蕴含的全人类知识,补充内容或拓展知识圈,总能找到一些新的知识来源、想法。
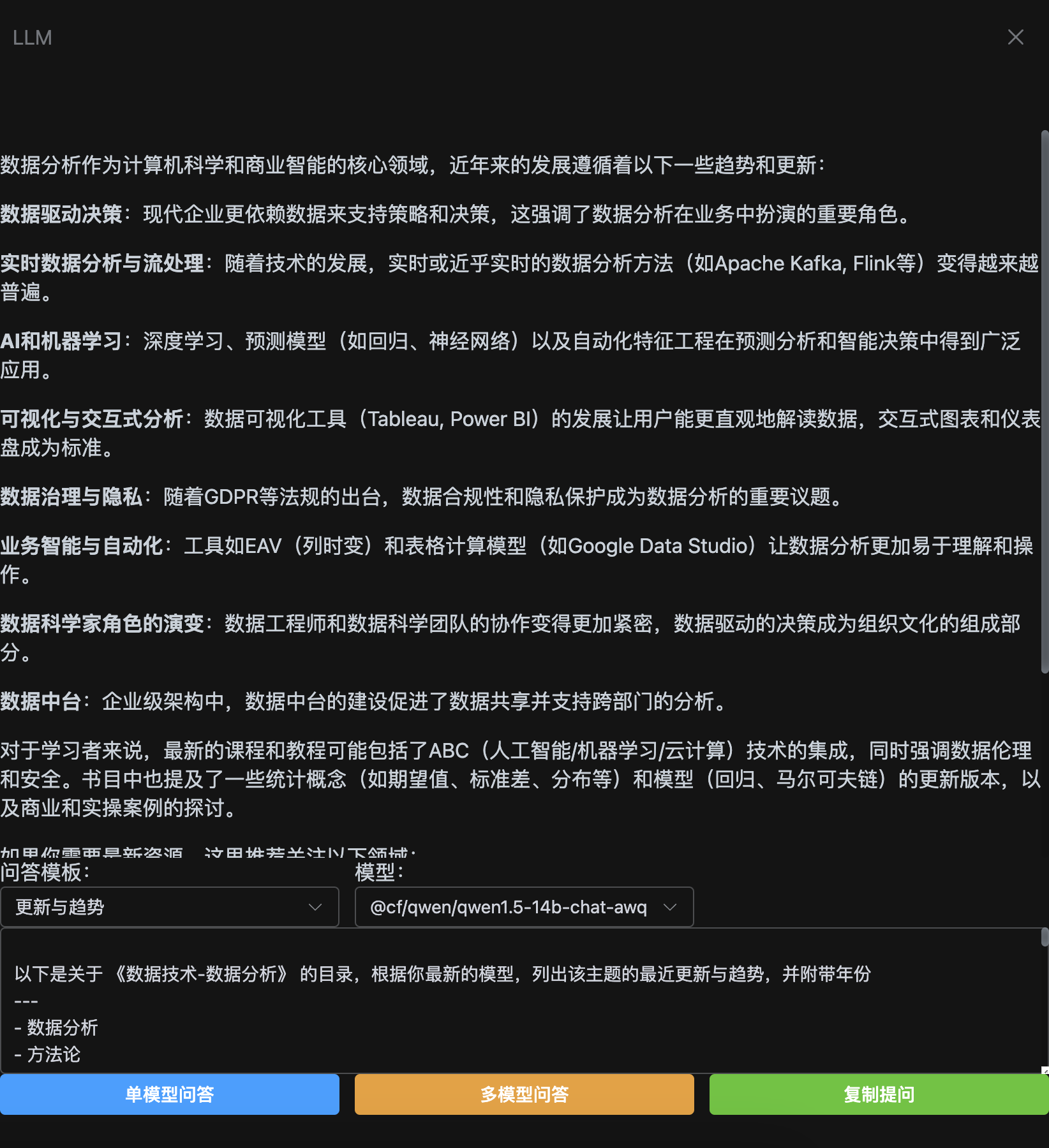
这是我总结的一些适合我自己的 LLM 模板,供参考:
async answerByContentTempalte() {
const file = await DocService.getDocFileInfo(this.doc)
return `
请根据以下文本回答问题:
问题:
文本:
---
${file.content}
---
`
},
async answerByAllCategoryTemplate() {
const categorys = await CategoryService.getCategoryList()
return `
以下是个人知识体系的目录,请根据目录回答问题:
问题:
目录:
---
${categorys2String(categorys, 0)}
---
`
},
async answerByCategoryTempalte() {
const contents = await DocService.getContentByDocId(this.doc)
const text = contents2String(contents)
return `
以下是关于 《${this.doc}》 的目录,请根据目录回答问题:
问题:
目录:
---
${text}
---
`
},
async futureTemplate() {
return `
简单介绍一下关于 《${this.doc}》 的未来可能得发展方向与挑战
`
},
async historyTemplate() {
return `
简单介绍一下关于 《${this.doc}》 的历史背景,重点放在关于 《${this.doc}》 的发展历程
`
},
async trendsTemplate() {
const contents = await DocService.getContentByDocId(this.doc)
const text = contents2String(contents)
return `
以下是关于 《${this.doc}》 的目录,根据你最新的模型,列出该主题的最近更新与趋势,并附带年份
---
${text}
---
`
},
async categoryTempalte() {
const contents = await DocService.getContentByDocId(this.doc)
const text = contents2String(contents)
return `
以下是关于 《${this.doc}》 的目录,还有哪些方面的内容还可以补充
---
${text}
---
`
},
async summaryTemplate() {
const file = await DocService.getDocFileInfo(this.doc)
return `
概括以下文本的内容:
---
${file.content}
---
`
},
在大模型时代,我们做知识体系的方式、内容也应该做出一点改变:
- 将重心放在构建整体的知识体系框架,细节的知识可以交由 LLM 来生成。
- 要构建可信的知识体系,由 LLM 生成的知识内容仍需审核。
- 利用以上手段,构建独属于自己的知识体系,后续能交由 LLM 检索,让 LLM 利用知识体系解决个性化的问题,并据此不断地完善知识体系,打造个性化的知识体系。