使用机器学习实现文档推荐与标签预测
这篇文章介绍了如何使用文本相似算法以及层次聚类算法来实现给定一篇文档,从而找出与该篇文章相似的 N 篇文档,不仅能用于文章推荐,也能用来预测文章的分类,标签等,让我们现在开始吧。
数据准备
这里我使用我个人的知识体系 https://github.com/0xcaffebabe/note 来作为文档来源,在本篇文章中,我将实现给定一篇文档,推荐出与这篇文章相似的几篇文档。
数据预处理
数据预处理是机器学习中很重要的一项准备工作,正所谓“垃圾进,垃圾出”,高质量的数据集对机器学习任务有很重要的意义。在本篇文章中,我们需要将文档转为一个个单词,再将每篇文章的单词转为一串向量。
所以,第一步,先过滤掉不参与学习的文档,这些文章是历史遗留下来的,对于本次机器学习任务没有太大意义,所以我通过指定一个 stopFiles 列表来过滤
const stopFiles = [
'SUMMARY.md',
'README.md',
'书单.md',
'参考文献.md',
'技术栈参考.md',
'leetcode.md',
'学习计划.md',
'基于位置的网络社交平台分析与设计.md',
'全文检索引擎在信息检索中的应用.md',
'MyBook.md',
]
第二步,我们需要指定一些停用词,因为这些停用词本身没有意义,对于机器学习任务来说是个干扰,所以指定一个停用词列表来去除,这里的停用词是我根据我自己的文档情况给出的
const stopWords = ['的', '是', '在', '一个', '和',
'与', '批注', '可以', '使用', '通过', 'md', '据库', '这个', '截图', '没有',
'进行', '如果', '需要', '务器', '屏幕', '不会', '就是', '或者', '并且',
'其他', '之后', '那么', '什么', '可能', '为了', '第一', '不是', '大小'
]
数据转换
分词
我们需要通过向量来计算两篇文档的相似度,如果把一篇文档的向量看作一个数组的话,那么数组元素的每一项就代表了文档的一部分特征,那么这部分特征应该如何取,取什么?方法有很多,这就是特征工程所要干的。
本篇文章中我使用词以及词出现的次数作为文档的特征。那么第一步就是要对文档进行分词,这里我采用 nodejieba 来完成这项工作。
词转为向量
接下来我们需要通过将一篇文档转为向量,将一篇文档转为向量的算法有很多,像是 word2vec、one-hot 编码、整数编码等。
这里我采用了 one-hot 编码,其原理就是首先统计所有文档出现过有哪些词,再对每篇文档进行处理,出现词的槽位设置为出现次数,没有出现的槽位就是0。
这种编码的问题就在于向量可能会特别长,而且可能会造成稀疏向量,即数组中的很多槽位都是 0。但对于我的数据来说,这并不是问题,因为我的这些文档基本上都是计算机相关的,常用词的也就哪些,同时文档数也不多,大概就 500 篇左右,所以内存消耗也不会很高。
比如,所有文档出现的词列表为
[篮球, 跳舞, 唱歌]
而 A 文档经过词分割后,“篮球”这个词出现了 2 次,“跳舞”这个词出现了 1 次,那么它的向量表示就是
[2, 1, 0]
这是将文档转为向量的代码
async function getAllWords() {
const fileList = BaseService.listAllMdFile()
const tasks = []
for(const file of fileList) {
tasks.push(fs.promises.readFile(file))
}
const buffers = await Promise.all(tasks)
const allWords = buffers.map(v => v.toString())
.map(cleanText)
.map(v => jieba.cut(v))
.flatMap(v => v)
.filter(v => !isStopWord(v))
const map = new Map<string, number>()
for(const i of allWords) {
if (map.has(i)){
map.set(i, map.get(i)! + 1)
}else {
map.set(i, 1)
}
}
totalList = Array.from(map)
.sort(function(a,b){return a[1] - b[1]})
.reverse();
}
const vecCache = new Map<string, number[]>()
function getDocVec(file: string): number[] {
if (vecCache.has(file)) {
return vecCache.get(file)!
}
const content = fs.readFileSync(file).toString()
const map = new Map<string, number>()
jieba.cut(content || '')
.filter(v => !isStopWord(v))
.forEach(i => map.set(i, (map.get(i) || 0) + 1))
const list = cloneDeep(totalList)
list.forEach(v => v[1] = map.get(v[0]) || 0)
const vec = list.map(v => v[1])
vecCache.set(file, vec)
return vec
}
相似度算法
为了衡量两个向量之间的相似度,有许多相似度算法,像是皮尔逊相关系数、欧几里得距离等等。这里我们采用余弦相似度来计算两个向量的相似度
function sim(vec1: number[], vec2: number[]) {
if (vec1.length != vec2.length) {
throw Error('长度不同')
}
let xPowSum = 0
let yPowSum = 0
let xmySum = 0
for(let i = 0; i < vec1.length; i++) {
xPowSum += Math.pow(vec1[i], 2)
yPowSum += Math.pow(vec2[i], 2)
xmySum += vec1[i] * vec2[i]
}
return xmySum / Math.sqrt(xPowSum * yPowSum)
}
层次聚类
接下来就是本篇文章核心算法了,这个算法的核心就是两两配对,找到每篇文档的最相似文档,组合成一个聚类,然后每个聚类都找到与本聚类最相似的聚类,组合成一个更大的聚类,以此类推。
局部视图:
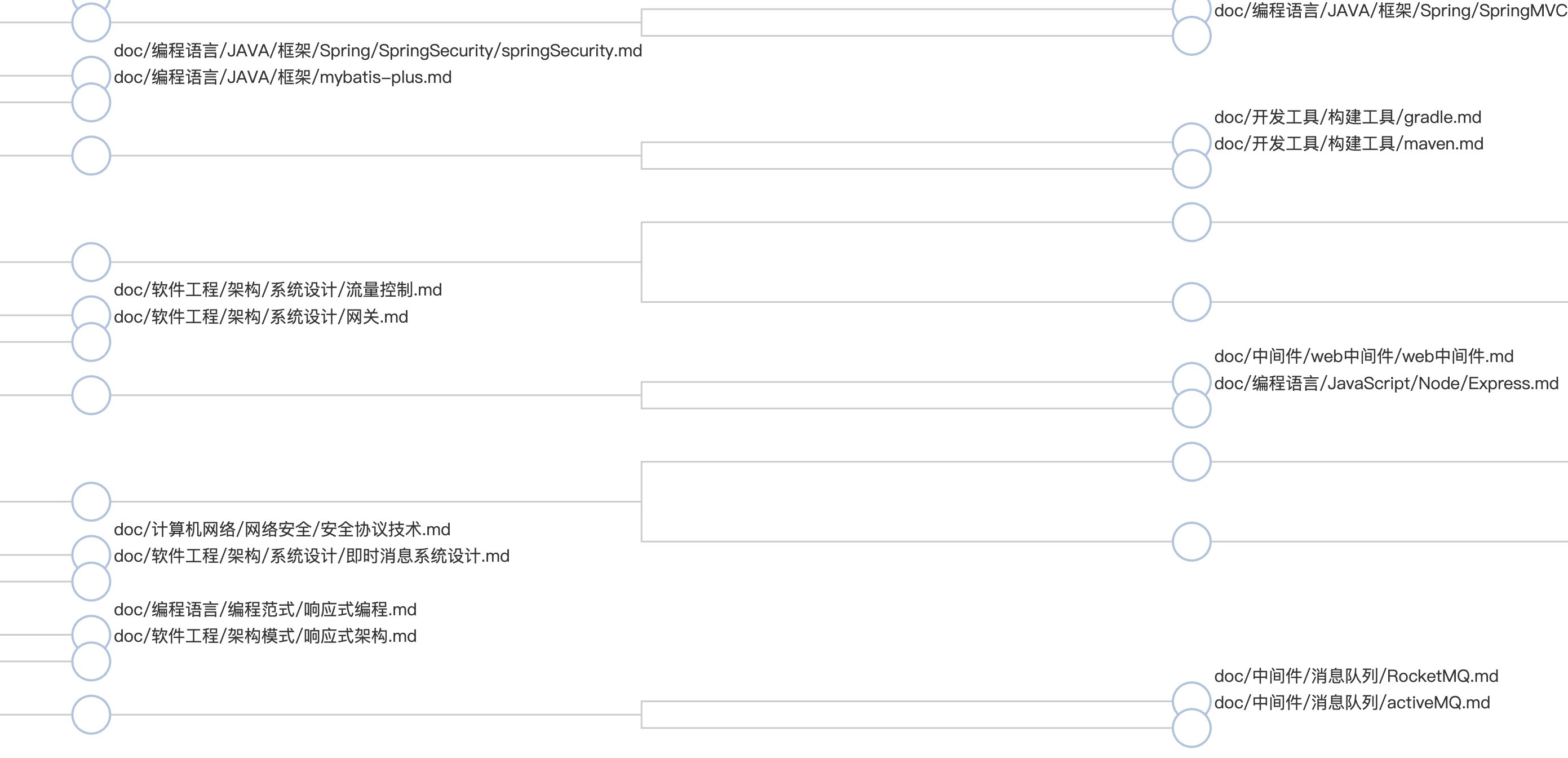
整棵树是这样子的:

算法的终止条件是最后只剩一个聚类。
这里有个细节问题需要明确:对于两个文档之间的相似度,其实就是针对两个向量计算余弦相似度。但两个聚类之间的相似度,应该如何计算的得出?
这里我采用了相加再平均的方式。即把两个聚类的所有文档再进行两两计算相似度,最后再将所有相似度加起来,除以两个聚类文档的数量
整个算法的代码如下:
async function main(ret = false): Promise<ClusterNode[]> {
await getAllWords()
const files = BaseService.listFilesBySuffix("md", "doc").filter(stopFileCheck)
const similarCache = new Map<string,number>()
// 聚类列表
const cluster: ClusterNode[] = []
for(const file of files) {
const node: ClusterNode = new ClusterNode()
node.name = file
cluster.push(node)
}
// 后N轮
while(cluster.length > 1) {
const cluster1 = cluster.shift()
// console.log(cluster1)
if (!cluster1) {
continue
}
let maxSim = 0
let simIndex = -1
for(let j = 0; j < cluster.length;j++) {
const cluster2 = cluster[j]
if (JSON.stringify(cluster1) == JSON.stringify(cluster2)) {
continue
}
let totalSim = 0
let cnt = 0
for(const file1 of cluster1.all()) {
for(const file2 of cluster2.all()) {
const key = file1 + "-" + file2
const key1 = file2 + "-" + file1
if (similarCache.has(key) || similarCache.has(key1)) {
totalSim += similarCache.get(key)! || similarCache.get(key1)!
}else {
const value = similar(file1, file2)
similarCache.set(key, value)
similarCache.set(key1, value)
totalSim += value
}
cnt++
}
}
if (cnt != 0) {
const sim = totalSim / cnt
if (sim > maxSim) {
maxSim = sim
simIndex = j
}
}
}
if (simIndex != -1) {
const newCluster = new ClusterNode()
newCluster.children = [cluster1,cluster[simIndex]]
cluster.push(newCluster)
cluster.splice(simIndex, 1)
// console.log(util.inspect(cluster.slice(Math.max(cluster.length - 5, 1)), {showHidden:false, depth: null, colors: true}))
}
}
if (ret) {
return cluster
} else {
fs.writeFileSync("./docCluster.json", JSON.stringify(cluster))
return []
}
}
结果
最后我将结果写到 json 文件中,来看看里面的数据是什么样的:
[
{
"name": "",
"children": [
{
"name": "",
"children": [
{
"name": "",
"children": [
{
"name": "",
"children": [
{
"name": "",
"children": [
{
"name": "",
"children": [
{
"name": "doc/通识/markdown写作.md",
"children": []
},
{
"name": "",
"children": [
{
"name": "doc/开发工具/idea.md",
"children": []
},
{
"name": "doc/软件工程/软件设计/代码质量/整洁代码.md",
"children": []
}
]
}
]
},
... 省略
应用
那么,这些数据我们如何应用呢?
给定一篇文档,我们可以遍历这棵树,把这篇文档所属节点的 N 个父节点的文档数据或 N 个子节点的文档数据作为其相似文档,这个 N 根据需求决定
public async getSimliarDoc(id: string): Promise<string[]> {
const clusters = await api.getDocCluster()
let node: ClusterNode | null = null
function travel(root: ClusterNode, round: number[]): [ClusterNode, boolean] {
if (DocUtils.docUrl2Id(root.name) == id) {
return [root, true]
}
let ret: [ClusterNode, boolean] | null = null
for(let i of root.children) {
const r = travel(i, round)
if (r[1] && round[0] > 0) {
node = root
round[0]--
return r
}
}
return ret || [root, false]
}
function all(root: ClusterNode): string[] {
return [root.name, ...root.children.map(all).flatMap(v => v)].filter(v => v)
}
travel(clusters[0], [3])
if (!node) {
return []
}
return all(node).filter(v => this.docUrl2Id(v) != id)
}
}
机器学习这篇文档的实际推荐效果:
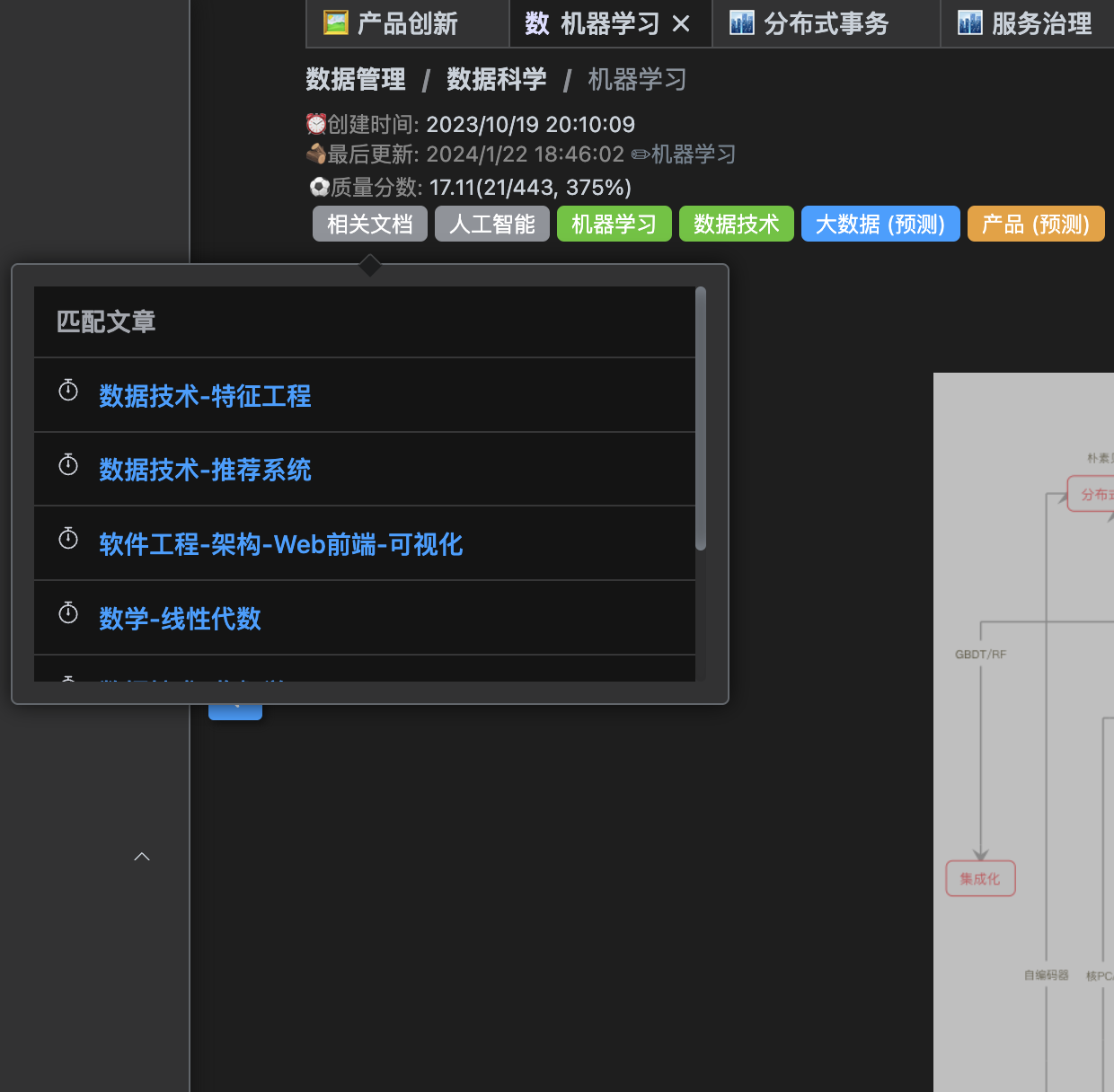
标签预测
那么,在上一步相似文档推荐的基础上,我们还可以实现标签预测。
标签预测的算法核心是将每篇文档与所有标签下的文档计算相似度,这样每篇文档就都有一个 (文档,【标签1,与标签1的相似度】,【标签2,与标签2的相似度】…) 的映射,只需要将相似度按低到高排序,取前 5 个标签作为预测结果就行了
预测的效果图如上,预测结果生成的代码如下
async function generateDocTagPrediction() {
await getAllWords()
const tagMapping = await DocService.buildTagMapping()
const files = BaseService.listFilesBySuffix("md", "doc").filter(stopFileCheck)
const mapping = new Map<string, [string, number][]>()
for(const file of files) {
const vec1 = getDocVec(file)
mapping.set(file, [])
for(const tag of tagMapping) {
let sumDis = 0
for(const tagFile of tag[1]) {
sumDis += sim(vec1, getDocVec(tagFile))
}
const avgDis = sumDis / tag[1].length
mapping.get(file)!.push([tag[0], avgDis])
}
mapping.get(file)!.sort((b,a) => a[1] - b[1])
mapping.set(file, mapping.get(file)!.splice(0,5))
}
const res = new Map<string, string[]>()
for(const file of files) {
res.set(file, mapping.get(file)?.map(v => v[0]) || [])
}
return Array.from(res)
}
预测结果:
[
[
"doc/DSL/CSS.md",
[
"DSL",
"算法",
"云原生",
"编程范式",
"人工智能"
]
],
[
"doc/DSL/GraphQL.md",
[
"中间件",
"es",
"架构模式",
"编程语言",
"大数据"
]
],
...
代码
这个算法的完整代码在 https://github.com/0xcaffebabe/note/blob/master/src/scripts/generateDocCluster.ts
根据文档找相似文档的代码在 https://github.com/0xcaffebabe/note/blob/master/src/service/DocService.ts#L565
文档标签预测结果生成的代码在 https://github.com/0xcaffebabe/note/blob/master/src/scripts/generateDocCluster.ts#L117